What are the Trade-Offs Between Brute Force and Tree-Based Indexing in Vector Databases?
Brute Force and Tree-Based Indexing
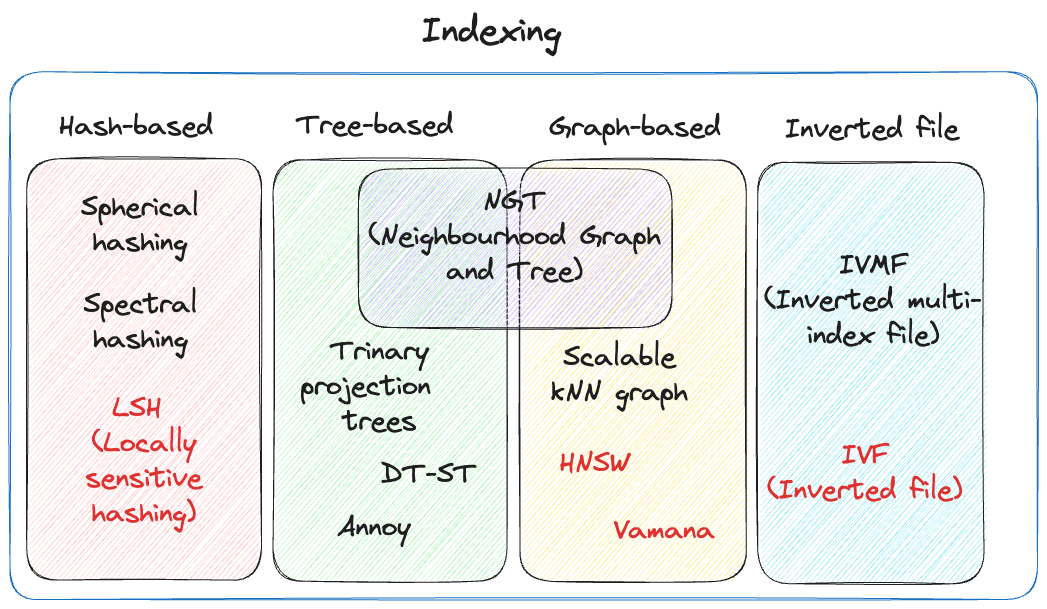
Vector databases are a crucial component of many AI applications, enabling efficient storage and retrieval of high-dimensional data. However, as the size and complexity of these databases grow, the need for efficient indexing techniques becomes increasingly important. Two popular approaches to indexing vector databases are brute force and tree-based indexing.
While both methods have their advantages and disadvantages, choosing the right approach can significantly impact the performance and scalability of your database. In this post, we'll explore the trade-offs between brute force and tree-based indexing in vector databases.
Understanding Vector Databases
Applications like machine learning and data analytics require high-dimensional vectors, which can only be handled by vector databases, which are specialized data storage systems.
Vector databases, as opposed to regular databases, are better at storing and querying data points expressed as vectors, allowing for faster and more exact similarity searches.
Brute Force Indexing
Brute force indexing is a straightforward method for indexing vector databases, although it is computationally costly. This approach locates the closest neighbors by comparing each vector in the database to the query vector. This method doesn't require complicated data structures or extra memory, making it easy to implement. But simplicity has a price: brute force indexing may be quite sluggish, particularly when dealing with big datasets.
I believe that brute force indexing is suitable for small to medium-sized datasets where query performance is not a critical concern. Additionally, this approach can be useful for prototyping or testing purposes, where simplicity and ease of implementation are more important than performance. However, for large-scale production environments, brute force indexing is often impractical due to its slow query performance.
Tree-Based Indexing
Using data structures like k-d trees, ball trees, or HNSW (Hierarchical Navigable Small World) graphs to arrange the vectors in a way that facilitates faster nearest neighbor search, tree-based indexing is a more efficient way to index vector databases—especially for large datasets. Tree-based indexing can significantly reduce the number of distance calculations required, which results in faster query performance and more efficient use of memory.
In my opinion, tree-based indexing is a more suitable approach for large-scale production environments where query performance is critical. This method can handle massive datasets and provide fast and accurate results, making it an ideal choice for applications such as image and video search, recommender systems, and natural language processing. However, tree-based indexing can be more complex to implement and may require additional memory, which can be a challenge for resource-constrained environments.
Trade-Offs Between Brute Force and Tree-Based Indexing
The trade-offs between brute force and tree-based indexing for vector databases must be taken into account when making this decision. Brute force indexing is simpler and easier to implement, but it results in slower query performance. Tree-based indexing, on the other hand, offers faster query performance, but requires more complex implementation and more memory. In my opinion, the decision between brute force and tree-based indexing ultimately comes down to the particular requirements of the application.
For instance, if query performance is crucial and the dataset is large, tree-based indexing may be a better option; however, if the dataset is small and simplicity is more important than performance, brute force indexing might be adequate.
Another important consideration is the dimensionality of the vectors. As the dimensionality increases, the complexity of the indexing method also increases. In high-dimensional spaces, tree-based indexing can become less effective, and brute force indexing may be a better option. Additionally, the type of query being performed also plays a role in the choice of indexing method. For example, if the application requires approximate nearest neighbor search, tree-based indexing may be more suitable. On the other hand, if exact nearest neighbor search is required, brute force indexing may be a better choice.
Ultimately, the choice between brute force and tree-based indexing requires a careful evaluation of the application's requirements and constraints. By considering the trade-offs between the two approaches, developers can make an informed decision and choose the indexing method that best meets their needs.
Conclusion
In conclusion, indexing is a crucial component of vector databases, enabling fast and efficient similarity search. Brute force and tree-based indexing are two popular approaches, each with their strengths and weaknesses. By understanding the trade-offs between these methods, developers can choose the best indexing approach for their specific use case.
For those looking to build scalable and efficient vector databases, Vectorize.io offers a powerful solution. As a cloud-based vector database platform, Vectorize.io provides a simple and intuitive API for indexing and querying large datasets. With support for both brute force and tree-based indexing, Vectorize.io allows developers to easily switch between indexing methods and optimize their application's performance.